About the VEDB
How many faces, bodies, and animals do people regularly see? How many vertical surfaces do we see compared to oblique or horizontal surfaces? How many different types of objects do people typically encounter, and where in the visual field do these objects land? How do we move our heads and eyes during different types of activities? How does this affect our visual input? What does the world, as experienced by acting human observers, really look like?
Vision is an active process, and in order to fully characterize natural scene statistics it is necessary to characterize what human observers actually fixate in the world. Vision researchers have been fundamentally constrained in the types of insights they can obtain due to limitations of the datasets available for study, including: small dataset size, narrow or otherwise unprincipled sampling of human visual experience, and photographer bias. In addition, many datasets sample broadly from static images on the Internet, but these do not capture dynamic experiences and still reflect aesthetic preferences and other photographic biases.
Our database creation is guided by the following three criteria:
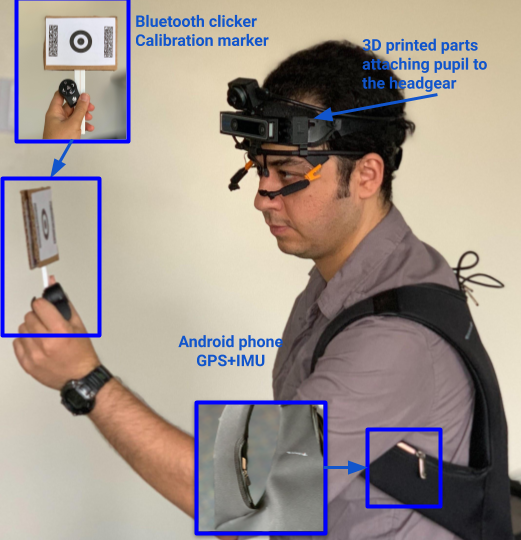
The data should be collected from a first-person perspective, with eye tracking. Cameras simulate first-person perspective, but are often aimed in ways that human eyes are not. Thus, it is critical that cameras be head-mounted and that eye tracking data be collected to reveal the specific objects, people, and locations that the observer is looking at.

The data should reflect a broad and unbiased sampling of locations, tasks, and events from daily life, across a wide variety of observers. Here, we take our cue from recent principled efforts to sample static images of scenes and objects based on natural frequencies, and extend the same logic to first-person video collection.

The database should be accessible to all, regardless of technical experience or skill. If one can query a search engine, one should be able to access these data in a usable format.
